
I've previously written about how we handle zero downtime deployments with Entity Framework and Migrations but the post lacked an important piece of the puzzle: how to drop a column.
When practising continuous deployment, in order to drop a column, you need to follow the drop column shuffle:
- Ensure that the column is nullable
- Remove all references to it from your application and deploy to live
- Drop the column from the database
If you're using Entity Framework with Migrations, the only way to stop your application from referencing a column in selects and updates is to remove it from the model. Unfortunately, this also means that EF will force you to create a migration with a statement to drop the column from the database (more on why can be found in this helpful article by Max Vasilyev).
To illustrate why this is a problem, let's assume that our deployment pipeline is as follows:
- Run migrations
- Deploy the application into the staging slot
- Wait for the application to respond to requests
- Swap the staging slot with the production slot
If we released the application change along with the drop statement, as soon at the migration was run (step 1), the live versions of the applications would start to error until step 4 when the new version has been completely deployed across all servers. Clearly, we need to decouple the application from the migration script.
The solution is that while EF migrations forces you to generate a migration script, it doesn't actually care what's in the script, just that one exists for model consistency. We can, therefore, simply delete the drop statement and deploy the application with a now empty migration.
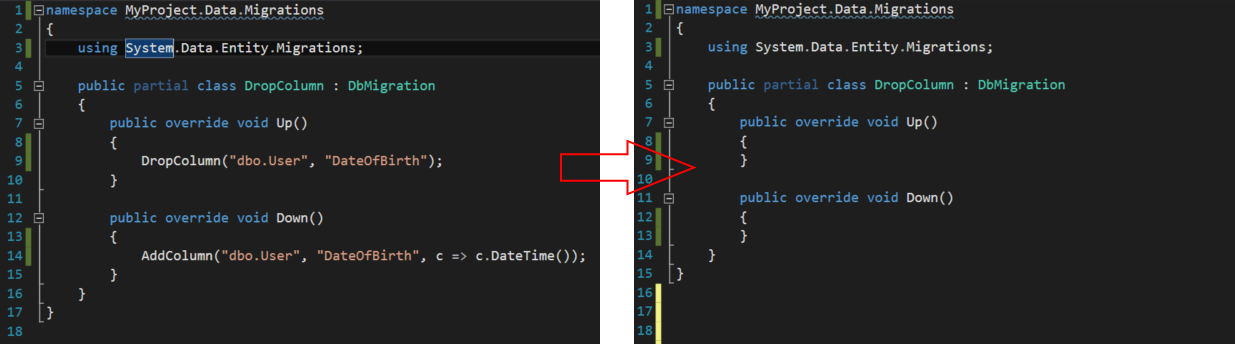
Finally, once the application is live, simply generate an empty migration, add back the drop statement and deploy the (unchanged) application along with the drop statement to live.

And that's all there is too it, fairly simple really. Next up, a more in depth article on how we do continuous deployment at Moneybox.